AWSのDynamoDBのデータを取り出して、CSVに保存する方法のメモです。
NoSQLであるDynamoDBは手軽なのでまずはデータを保存したりしているのですが、データを取り出してExcelでグラフを描きたい時にCSVに出力すると便利なことがあります。
準備: AWS CLI と boto3 をインストール
ローカルPCでAWSにアクセスするにはAWS CLIが必要です。
pythonからdynamoDBを扱うにはboto3も必要です。
$ pip3 install boto3
プログラム
python3です。
dynamoDBテーブル: mydynamo から
Primary Key: hostname が ‘hoge_host_1’
Sort Key: timestamp が ‘2019-11-11’ から ‘2019-11-22’ の間の type=1 に一致するデータを取得してouutput.csv ファイルへ出力します。
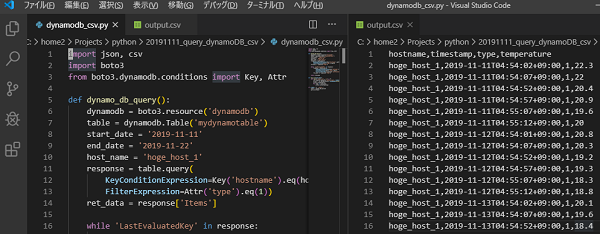
import json, csv
import boto3
from boto3.dynamodb.conditions import Key, Attr
def dynamo_db_query():
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('mydynamotable')
start_date = '2019-11-11'
end_date = '2019-11-22'
host_name = 'hoge_host_1'
response = table.query(
KeyConditionExpression=Key('hostname').eq(host_name) & Key('timestamp').between(start_date, end_date),
FilterExpression=Attr('type').eq(1))
ret_data = response['Items']
while 'LastEvaluatedKey' in response:
response = table.query(
KeyConditionExpression=Key('hostname').eq(host_name) & Key('timestamp').between(start_date, end_date),
FilterExpression=Attr('type').eq(1),
ExclusiveStartKey=response['LastEvaluatedKey'])
ret_data += response['Items']
return ret_data
def put_csv(list_data):
with open('output.csv', 'w') as f:
csv.register_dialect('dialect_name', doublequote=True, quoting=csv.QUOTE_ALL)
writer = csv.DictWriter(f, fieldnames=sorted(list_data[0].keys()), dialect='dialect_name')
writer.writeheader()
for item in list_data:
writer.writerow(item)
if __name__ == '__main__':
items = dynamo_db_query()
put_csv(items)
dynamo_db_query()
クエリを実行してdict型で値を返します。
CSV出力
csv.register_dialect を使う方法 put_csv(list_data)
上のコードではdict型データを受け取り、csvファイルへ出力します。
print()による put_csv(list_data)
dict型データを受け取りprint()を使ってCSVファイル出力する方法はこちら。
dictデータをlistに変換してjoinで1行を文字列にして出力しています。sorted()でソートした順です。
import codecs
def put_csv(list_data):
outfile = 'output.csv'
header = []
for item in sorted(list_data[0].keys()):
header.append(item)
print(','.join(header), file=codecs.open(outfile, 'w', 'utf-8'))
for item in list_data:
list_buf = []
for key in sorted(item.keys()):
list_buf.append(str(item[key]))
print(','.join(list_buf), file=codecs.open(outfile, 'a', 'utf-8'))
print(‘,’.join(header)) にすれば標準出力されますのでリダイレクトしてもOK。
hostname,timestamp,type,temperature hoge_host_1,2019-11-11T04:54:02,1,22.3 hoge_host_1,2019-11-11T04:54:07,1,22 hoge_host_1,2019-11-11T04:54:52,1,20.4 hoge_host_1,2019-11-11T04:54:57,1,20.9 hoge_host_1,2019-11-11T04:55:07,1,19.6 hoge_host_1,2019-11-11T04:55:12,1,20 hoge_host_1,2019-11-12T04:54:01,1,20.8
まとめ
クソコードですが、とりあえずCSVに出力できました。
関連記事
PythonでDynamoDBのQueryを実行する
AWS LambdaからNode.jsでDynamoDBのクエリを実行する。
AWS dynamoDB のキーに予約語timestampを使用している場合のCLIからのquery